本研究通过模仿尝试,从4种分歧的项目功能差别查验方式中甄选出最适合用来阐发高评语文做文试题城乡公允性的一种,即基于PCM的Conquest内置DIF查验法。利用这种方式对2015年高评语文做文试题进行查验,成果表白该题不存正在显著的城乡差别。本文中的模仿尝试方式为从国际经验当选取适合我国的方案堆集了必然经验。项目功能差别查验则可认为提高命题质量,确保试题公允性供给根据。
近年来,社会对高考公允性的关心曾经逐渐由法式公允扩展到了测验内容对分歧群体学生能否公允上来。出格是高评语文做文题的公允性,曾惹起的热议。例如,2015年的陕西省高评语文做文题为就女大学生举报正在高速上违反交规的父亲激发的争议,给女儿、父亲或其他相关方写一封信。有一种概念认为这道题对于不领会高速公及高速上不克不及机等的农村塾生不公允。
国际上已有良多成熟的统计模子来估算试题对于分歧群体难度能否存正在显著差别。项目功能差别(Differential Item Functioning,DIF)查验是最合适、也是目前最常用的辨别试题能否存正在对某些群体不公允环境的方式。具体来说,DIF是指分歧群体(如分歧性别、族裔或地域等)的被试,正在能力不异时,正在某试题上得分几率的差别。当差别较大时,即DIF指数的绝对值正在统计上显著大于临界值时,被试正在该题上的得分就不只仅取决于他/她的学问或能力,而是正在很大程度上还取决于被试所属的群体,该题对分歧的群体就不公允。例如,正在提到的做文题中,若是学生得分的凹凸仅取其做文程度相关,则试题没有DIF;但若是学生由于糊口正在偏僻农村,不熟悉高速公等布景学问,从而无法一般完成做文,则可能呈现显著的DIF。
现实上,正在国际上较为出名的大型尺度化测验中,计较项目标公允指数曾经是题库扶植和的一项常规性工做,但我国正在这方面的研究还较少。此中一个主要的缘由正在于已有的统计模子都是针对国外尺度化测验的,试题绝大部门为客不雅题(如单项选择题、判断题等),且试题的评分品级凡是只要5个摆布。而正在我国的高考中,客不雅题占领了相当的比沉,且评分品级常常多达20个,做文题的评分品级理论上多达61级,数据布局取国外尺度化测验存正在显著的差别。因而,已有的统计方式不必然合用。针对上述问题,本研究先通过模仿尝试,从已有的DIF查验方式中甄选出最优方案,再以2015年语文高考的数据为例,查验做文的城乡公允性。
第三步,确定婚配变量。因为DIF不是间接对比两组被试的得分凹凸,而是对比分歧组中能力不异的被试正在某道试题上的得分环境,因而,需要先估算被试的能力,再对同样能力的被试进行对比。被试能力,凡是就是DIF阐发中的婚配变量。婚配变量有两类:考试总分(即原始分),或是由项目反映模子(item response model)估算的被试的潜正在实正在能力(即潜变量)。
第四步,估算DIF指数。按照能否利用项目反映理论或其他丈量模子,查验DIF的方式能够响应地分为两类:参数查验方式(利用项目反映理论或其他丈量模子的方式)和非参数查验方式(晦气用项目反映理论或其他丈量模子的方式)。表1展现了每个类别中的一些常用的查验方式。

第五步,对于统计方式识别出来的有显著DIF的试题,还需要进一步阐发可能的缘由和对应的点窜法子。
表1中枚举的方式都合用于一般尺度化测验中的选择题和分步计分题。可是要用来阐发高考做文题时,需要先处理两个问题。
第一个问题是找到婚配变量。过去的尺度化测验往往是单一维度的,也就是说所有的试题都正在丈量统一种潜正在能力。此时,婚配变量能够采用总分或由项目反映理论计较出的潜正在能力。近年来,越来越多的测试是度的。当每个维度有相当数量的试题时,研究者能够用该维度的总分或该维度能力潜变量估值做为婚配变量。正在高评语文中,测试学生做文能力的题仅有1道做文题。若是简单地用语文总分或语文能力潜变量,很可能无法较为精确地婚配能力不异的考生。当测试中没有不异类此外试题时,婚配变量只能用所测能力最接近的试题组来取代。除做文题外,高评语文试卷正在内容上还包含阅读和表达两大类;从题型来说,也有选择题和题两类。我们别离计较了分歧内容的得分、分歧题型的得分取做文得分的相关系数,成果如表2所示。从表2能够看出,题取做文成就的相关性最高,根基达到了婚配变量的利用尺度,因而,我们将12道题的成就(或由此估算出的潜正在能力)做为婚配变量。

第二个问题是模子能否能处置多评分品级的项目。正在常见的尺度化测验中,单项选择题是0/1计分,分步计分题大大都采用0~5之间的整数,很少有跨越10个分值级此外。但正在高考做文中,总分为60分,理论上就有61个评分品级。正在已有的理论研究和阐发中,尚未测验考试过度析这种形态的数据。因而,我们无法间接判断哪种模子能最切确地查验出DIF。
为了选出查验高评语文做文题能否存正在DIF的最佳方式,我们从分歧参数类型和婚配变量类型中,各拔取1~2种较为常用的方式,通过模仿研究,来比力哪种方式能更活络、更切确地检测出雷同高考做文分数的数据中的DIF。具体来说,我们拔取了以下4种DIF查验的方式:P-MH、P-S、P-SIBTEST和基于PCM(Conquest内置)的DIF查验方式。
正在模仿研究中,除了这4种方式外,还有2个主要的节制前提。一是DIF的大小。因为不晓得高考做文题能否存正在DIF或DIF的效应值多大,我们设定了3种环境,即很小(可忽略,效应值为0.1)、中等大小(效应值为0.5)和严沉DIF(效应值为0.8)。第二个节制前提是试题的评分品级数。高考做文题虽然理论上有61个品级,但正在现实测试中,并非所有品级城市被经常利用。没有利用到或很少被利用的分数品级往往会被归并。因而,我们正在模仿研究中也设置了3种分歧的分数品级:10(0~9分)、21(0~20分)和41(0~40分)。如许,成果对于其他10~20级评分的题也有自创意义。综上,模仿研究采用了4×3×3的完全随机设想(即4种DIF查验方式、3种DIF大小、3种分数品级)。
3)随机生成16524个被试的能力参数(同数据的样本量),随机将1/3的被试分为方针组(农村),2/3为参照组(城市)。
5)采用倾向性婚配法,按照“做文题”以外的19道题的得分环境,将两组被试进行婚配。
6)随机抽样。当样本量太大时,任何细小的差别城市被检测出来,从而放大“Ⅰ类错误”的概率。因而,样本量并非越大越好。按照董圣鸿等人的模仿研究,SIBTEST方式的样本量正在1000~2000时,就能获得很好的DIF检出结果。因而,本研究对能力婚配后的5718对样本进行随机抽样,最初获得1000对样本(城乡被试各1000人)。
7)别离采用P-MH、P-S、P-SIBTEST和Conquest内置DIF查验方式,对随机抽样获得的做答数据进行DIF查验,记实每一次运算的成果。
正在获得对模仿数据的DIF查验成果后,我们根据该方式犯“Ⅰ类错误”概率和统计查验力来比力4种方式的好坏。所谓“Ⅰ类错误”,就是指把一些没有DIF的项目错误地检测为存正在DIF的环境。若是某种DIF检测方式犯“Ⅰ类错误”的概率较高,那么这种方把某些高质量的、没有DIF的项目误判为存正在DIF,对DIF实正缘由的检测带来很大的搅扰。统计查验力则是指某种方式准确查验呈现实存正在DIF的能力。
正在模仿研究中,我们次要采用统计软件R和项目反映模子软件ConQuest来进行数据阐发。此中,利用P-MH和P-S方式时,采用了R言语的自编法式;利用P-SIBTEST方式时,采用了R言语中的mirt包;利用基于PCM的方式时,采用了ConQuest软件。
模仿研究的成果见表3~表5。表3展现了当DIF很小,正在统计上能够忽略不计时,4种方式犯“Ⅰ类错误”的概率。P-S和基于PCM的方式表示较好,没有呈现“Ⅰ类错误”。P-SIBTEST最差,“Ⅰ类错误”率正在处置41级计分时高达98%。P-MH和P-SIBTEST呈现“Ⅰ类错误”概率较高的缘由可能是χ2统计量对样本量变化,当样本容量较大时,细小的差别城市形成显著的查验成果。

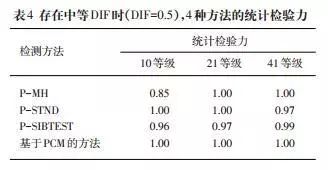
表4显示了当DIF为中等大小时,4种分歧方式的统计查验力。能够发觉,基于PCM的方式正在处置10级、21级和41级计分的项目中都表示最佳。P-S正在处置10级和21级计分的项目时也达到了100%的检出率,但正在处置41级计分的项目时,检出率略低于基于PCM的方式。P-MH朴直在处置10级计分项目时稍显不脚。
从表5我们能够看出,当DIF较大时,基于PCM的方式再次显示了最强的统计查验力。P-S正在这种环境下,和基于PCM的方式八两半斤。另两种方式虽然都有所提高,但仍然低于P-S和基于PCM的方式。

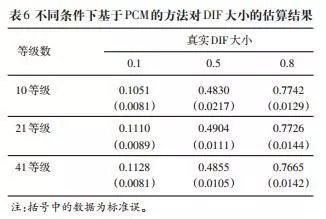
由此可见,基于PCM的方式正在各类环境下都最为活络和精确。这种方式对DIF参数的估算取我们设定的值十分接近(如表6)。颠末100次反复模仿,当项目为10级计分时,这种方式对DIF指数的估值是0.1051,尺度误为0.0081,取设定值的差别正在统计上不显著。从全表来看,当实正在的DIF值(设定值)较小时,这种方式倾向于高估DIF指数,计分品级越多,高估倾向越较着。当实正在的DIF值(设定值)较大时,这种方式倾向于低估DIF指数,计分品级越多,低估倾向越较着。但估量值取实正在值的差别都不显著。因为基于PCM的方式犯“Ⅰ类错误”的概率更小,统计查验力更高,估算计为精准,因而是检测高考做文题能否存正在DIF的首选。
模仿尝试表白基于PCM的方式正在前述4种方式中最适合用来查验高考做文题能否存正在DIF。因而,我们用这种方式对2015年高评语文做文题进行了阐发。从东北部某省的考生中随机抽取16524个样本(该省总样本量的5%),此中城市学生5718名,农村塾生10806名。初步的统计描述成果显示,城市学生平均做文成就为40.44分,农村塾生平均做文成就为39.95分。虽然两组学生成就差别的t查验显著,但现实效应值很是小,仅为0.114。
随后,利用2015年语文试卷中的12道题做为锚题,对考生进行能力婚配。使用ConQuest内置的法式进交运算。成果显示,12道题加1道做文题(共13题)的总体信度为0.66。试题取分步计分模子(PCM模子)的拟合优良。DIF指数为0.012,也就是说做文题对城镇学生比对农村塾生难度差别为0.012,这一差别很是细小,现实的效应值低于Paek指出的临界值0.426,因而能够忽略。因而,2015年高评语文做文试题不存正在显著的城乡差别。
公允是高考的根基要求,确保试题对分歧群体考生公允是高考命题和题库扶植十分主要的环节。DIF阐发可认为试题的公允性供给根据。正在本研究中,通过模仿尝试对现有的DIF查验方式进行了甄选,并测验考试使用选出的最佳方式阐发数据。
本研究还存正在一些局限性:一是对学生城乡布景的划分基于户籍。跟着我国城镇化的飞速成长、生齿向县城集中等要素,用学生现实糊口所正在地来划分会愈加科学。二是正在的阐发中,只关心了城乡DIF,而性别DIF、平易近族DIF等也是试题公允性不成轻忽的部门。
统计方式为查验DIF供给了手段,将来还需要对存正在DIF的试题进行深切的质性阐发,寻找形成DIF的可能缘由。只要正在命题中避免了这些要素,命题质量才能不竭提高。
